
In our daily lives, we are exposed to a myriad of chemicals in the environment and goods, such as food, toiletry products, and plastic containers. Despite constant institutional efforts, laboratories worldwide have been able to assess a small fraction of these chemicals for harmful effects, and the reason is that evaluating each of them, on average, takes years and is very costly.
Toxicity prediction through computational methods is crucial to help accelerate the identification of harmful substances, significantly lowering the costs and reducing animal testing.
Over the years, researchers have explored classical machine-learning methods to identify molecules, predict protein function, and discover medicines using graphs. The main idea of graph methods is to represent data in a simple drawing using dots (vertices) and lines connecting them (edges).
It may sound simple; however, graph-based data can be tremendously challenging to manipulate. A technique that has been successfully implemented in graph machine learning uses a mathematical object called kernel, which simplifies tasks dramatically.
Inspired by graph kernel methods, scientists at PASQAL have developed a novel quantum machine learning algorithm called Quantum Evolution Kernel (QEK). They successfully applied this method — on our neutral atom quantum processor — to predict the toxicity of chemicals included in the dataset of the Predictive Toxicity Challenge on Female Mice. The challenge consists of creating models to identify substances that cause cancer in mice based on the molecular structure of the chemicals.
This is the first time a quantum graph machine learning algorithm has been implemented on neutral atom hardware, showcasing the potential advantage of the QEK algorithm. We published the results today in the arXiv.
“This is a great achievement because the data set is huge, there are hundreds of graphs, and for each graph, you need to run many samples. This is the first time we are able to encode a large data set associated to a real case, not a toy model,” says Loïc Henriet, Chief Technical Officer at PASQAL.
But before we dive into the details of PASQAL’s quantum evolution kernel method and how our developers applied it to predict toxicity in chemicals, it is essential to understand the key ideas behind classical kernel machine learning techniques. Let’s look into them.
Dealing with a universe of data through a kernel
Imagine that you are a librarian and need to classify books, but everything you have is text fragments — loose words, phrases, sentences, and paragraphs of those books. Millions of text fragments. With them, you create an index to control the information. However, classifying books by searching in an extensive index of text fragments by hand is a highly inefficient procedure; therefore, you use a computer. For the computer to help, you translate the index into mathematical objects (find an embedding for the data). In many cases, vectors (arrays of ordered numbers) are very helpful.
However, in computational methods, there is a problem of balance: the more text fragments you include in the index, the more chances you have to succeed in classifying books (expressivity). However, the vectors may get so large that they burden the computer (computation and storage overload).
Here is where the kernel method comes to the rescue. The kernel is a quantity that can be defined using vectors, for example, calculating their inner product. The kernel can be interpreted as a “distance”–and should have the properties of a distance–that tells you how similar or different two books are, without having to store the vectors. Thus, the procedure is summarized as follows: take two books and construct a vector for each book based on your index. With these two vectors, calculate the kernel. The value of the kernel will tell you if they are the same book, similar, or very different.
In this same way, we can use kernel machine-learning methods to compare and classify chemicals from their molecular structure.
Kernel methods in quantum computing
Quantum computing is based on quantum physics, which is naturally defined in an ideal mathematical setting to embed data and define a kernel. This mathematical setting is the space where the quantum states of the atoms and molecules live, which are represented as vectors. This space is exponentially large, suitable to play with when increasing the number of qubits.
To define a quantum kernel, PASQAL developers use a property that can be measured after the evolution in time of a quantum system. However, in quantum mechanics, we cannot calculate the outcome of a property but its probability. Thus, the quantum kernel is defined as a “distance” between the probability distributions of a property of two quantum systems, for the same sequence repeated many times.
These are the core ideas behind PASQAL’s Quantum Evolution Kernel method.
How did PASQAL scientists conduct the experiments in our neutral atoms’ architecture, successfully implementing QEK to predict carcinogens in mice? Let’s dive into the experiments.
Molecules recreated in a neutral atom quantum processing unit
With PASQAL’s neutral atom quantum processor, our scientists represent molecules as graphs, physically recreating them in arrays of rubidium atoms. They organize these arrays by firing focused laser beams, known as optical tweezers, onto the atoms, creating the shape they desire.
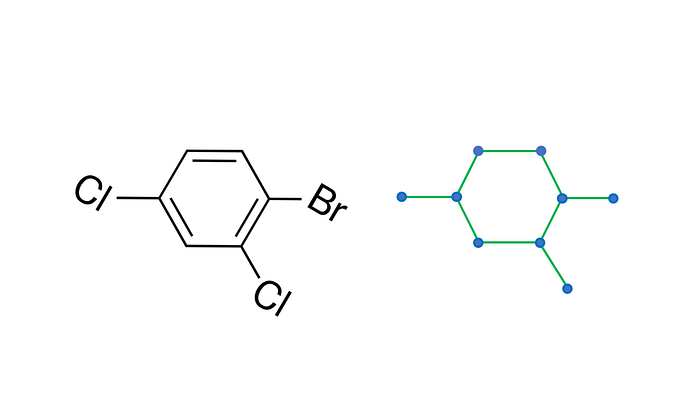
Once the atoms, representing the vertices of the graph, are in position, our developers use another set of fine-tuned laser beams to couple two atomic states together, creating a qubit with each atom.
A qubit is the quantum computing information unit represented by a two quantum states (|0⟩ and |1⟩). For this experiment, |0⟩ is ground state of the atoms and |1⟩ is their Rydberg state.
The Rydberg state is a very high energy level in an atom making the atom “grow”, which helps promote interactions with their neighbors in a controlled fashion to recreate the desired graph.
In this way, our developers recreate a molecule in the hardware, where each qubit represents the position of an atom and the interactions between the qubits represent their chemical bonds.

Predicting toxicity with Quantum Evolution Kernel
Once the system is ready, as described in the previous section, the graph is in its initial quantum state for the quantum evolution kernel to enter into action. The procedure involves promoting the graph’s evolution in time by firing tuned lasers pulses for a short period.
After the system has evolved to a new quantum state, the scientists measure a global property of the graph, such as the total number of its excited states. Then, they repeated this procedure several times, so that they ended up with a collection of moments — like pictures in a movie.
With this collection of moments, our developers construct a histogram which is interpreted as the signature of the graph. Then, for the classification task, they compare the signature of two graphs to assess their similarities.
Strength and limitations of QEK experimental implementation in toxicity
A key feature of our method is that it not only evaluates the local properties of the graph (its vertices and their interactions) but also global ones, such as the presence of cycles. The ability to compare global shapes is crucial to understanding molecular structures and predicting their function. This enrichment provided by PASQAL technology contrasts with many other classical graph machine learning methods, such as Message Passing Neural Networks that are only able to compare the graphs locally (the vertices and their number of neighbors connected to them), but not the entire graph with its global shape.
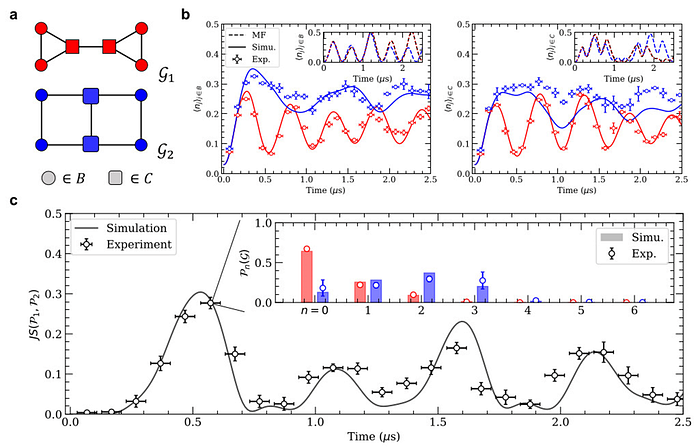
Moreover, our Quantum Evolution Kernel method — experimentally implementing the Predictive Toxicity Challenge data comprising 286 molecules of sizes ranging from 2 to 32 atoms— returned comparable scores with other well-known classical graph machine learning methods, such as Random Walk and Graphlet Sampling.
“It is great to see in practice, in real life, something that was just an idea before. We are solving a real problem with a real biochemistry data set. And this is something that you could see, the pictures of the atoms forming a molecule and seeing the output of the results doing what it was supposed to do; really apply quantum computing to a real problem was very exciting,” Loïc Henriet expresses.
However, despite its success, this result is still proof of concept. So far, “we have been working with one data set only, and to be able to prove something, we will need larger graphs, or larger data sets, or be more diverse, addressing other problems. In the landscape of quantum machine learning for graph data sets, this is just one point, and we will need to run more experiments to assess the viability of this new quantum paradigm compared with classical machine learning methods,” Loïc Henriet clarifies.
Many impactful applications arise from efficient graph-based methods. They help solve challenging problems, such as describing social networks, predicting protein function, representing structures in linguistics, detecting frauds, and predicting toxicity.
It is, therefore, essential to create efficient machine learning models that correctly and effectively learn and extract information from graph structures.
We are certain that PASQAL quantum computing methods, implemented in our scalable neutral atoms’ hardware, will help accelerate toxicity classification, reducing costs and animal suffering in experiments.
Do you have any questions about our technology and applications? Don’t hesitate to reach out to us!
References
- Helma, C., King, R. D., Kramer, S., & Srinivasan, A. (2001). The Predictive Toxicology Challenge 2000–2001. Bioinformatics, 17(1), 107–108. https://doi.org/10.1093/bioinformatics/17.1.107.
- Henriet, L., Beguin, L., Signoles, A., Lahaye, T., Browaeys, A., Reymond, G. O., & Jurczak, C. (2020). Quantum computing with neutral atoms. Quantum, 4, 327. https://doi.org/10.22331/q-2020-09-21-327.
- Henry, L. P., Thabet, S., Dalyac, C., & Henriet, L. (2021). Quantum evolution kernel: Machine learning on graphs with programmable arrays of qubits. Physical Review A, 104(3). https://doi.org/10.1103/physreva.104.032416.
- Albrecht, B., Dalyac, C., Leclerc, L., Ortiz-Gutiérrez, L., Thabet, S., D’Arcangelo, M., Elfving, V., Lassablière, L., Silvério, H., Ximenez, B., Henry, L.-P., Signoles, A., and Henriet, L. (Nov 29, 2022). Quantum Feature Maps for Graph Machine Learning on a Neutral Atom Quantum Processor. Preprint available: https://doi.org/10.48550/arXiv.2211.16337.
Writer: Alexandra de Castro. Scientific Contributors: Loic Henriet and Vincent Elfving.

")
